

In April 2019, predictions made on the World Economic Forum estimated the entire digital universe would reach 44 zettabytes (or 44 billion terabytes) by 2020, with 16 billion terabytes created in 2018 alone. As we continue to create data at extraordinary rates, we inevitably face a data storage crisis. Facebook, for example, has acquired roughly 15 million square feet of data center space. Could DNA be the future of data storage? We cover the basics of innovative DNA-based data storage this week so that you can Live Easy.
DNA synthesis and sequencing: writing and reading the code
DNA is the carrier of genetic information in nearly all living organisms. This information is stored as a code made up of four chemical bases: adenine (A), guanine (G), cytosine (C), and thymine (T). The order of these bases – called the sequence – then determines what information is available for building and maintaining an organism.
DNA bases pair up: A with T, and C with G. These base pairs, along with a couple of other components (sugar and phosphate), then arrange themselves up along two long strands to form the ladder-like helix we’re so accustomed to seeing when we think about DNA.
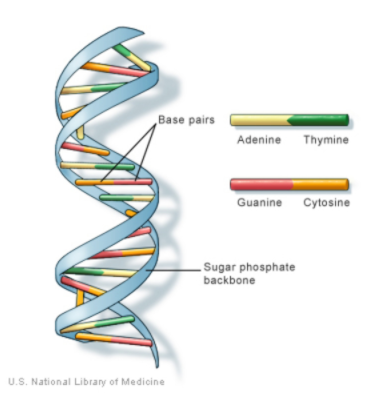
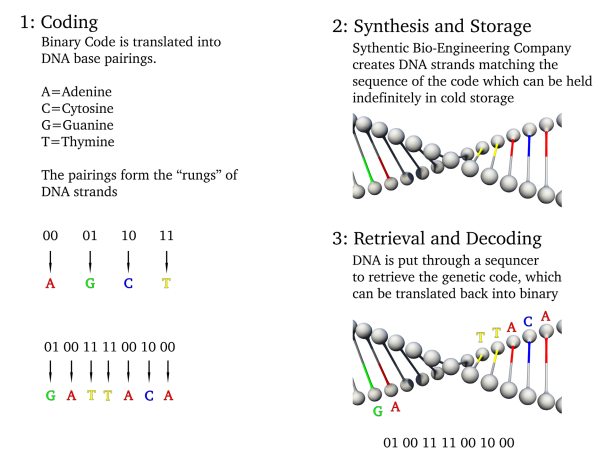
What does this all have to do with data storage? As it turns out, binary code (all those 0’s and 1’s) can be translated into DNA base pairings.
DNA data storage is the process of encoding binary data into synthetic strands of DNA. Binary digits (bits) are converted from 0s and 1s to the four chemicals bases (A, T, C, and G), such that the DNA sequence corresponds to the order of the bits in a digital file. In this way, the physical storage medium becomes a man-made chain of DNA.
Recovering the data is then a matter of sequencing that DNA. DNA sequencing determines the order of those four chemical building blocks, or bases, that make up the DNA molecule, and is generally used to determine the genetic information carried out in a particular DNA strand.
By running digital data-containing synthetic DNA through a sequencer, the genetic code – or sequence of bases – can be obtained and translated back into the original binary bits to access that stored data.
Protomac Institute for Policy Studies 2018
Advantages of DNA-based data storage
Density
DNA’s information storage density far-surpasses that of any known storage technology to date. Flash memory, for example, can store one bit of data in about 10 nanometers, while DNA can easily store two bits per 0.34 nanometers. And, while one kg of DNA can store 2×1024 bits, storing this much information would require more than 109 kg of silicon for flash memory.
We have over 32.7 trillion cells in our body, each with a copy of our entire DNA. DNA is so compact, scientist Karin Strauss – a principal research manager at Microsoft – estimates that a DNA system could store one exabyte (or 1 million terabytes) per cubic inch: “What requires a whole datacenter to store data today would fit in the palm of your hand.”
Stability
The stability of storage solutions remains a major challenge to overcome in the data storage crisis. If these solutions do not degrade over time, they become obsolete within the span of a few decades. When was the last time you bought a laptop with a CD reader?

DNA is an incredibly stable molecule with a half-life of over 500 years. If stored in the right conditions, it can remain intact for hundreds of thousands of years. Back in 2013, for instance, the DNA of a 700,000-year-old horse (stored in the permafrost) was sequenced.
DNA-based data storage can allow us access to today’s invaluable data centuries from now. And, as long as there is life, there is a need to read and manipulate DNA.
Energy consumption
We already know about the growing need for green data centers and corporate environmental responsibility as our data storage crisis wreaks havoc on environmental efforts. Massive data centers from the world’s most renowned tech organizations and cloud service providers come with equally high energy demand and consumption.
With the density and stability of DNA data storage, the digital information in a warehouse-sized data center could be stored in a space no larger than a sugar cube, requiring little energy to maintain. So, who’s making their name in the DNA data storage game then?
DNA data storage players making headlines
Microsoft
In March of 2019, in collaboration with the University of Washington, Microsoft demonstrated the first fully automated system to store and retrieve data in synthetic DNA. The team of researchers successfully encoded the word “hello” in segments of manufactured DNA and converted it back to digital data via a fully automated end-to-end system. This system is described in a paper published in Nature Scientific Reports on March 21, 2019.
Strauss elaborates, “Our ultimate goal is to put a system into production that, to the end user, looks very much like any other cloud storage service – bits are sent to a datacenter and store there and then they just appear when the customer wants them.”
Doris
From North Carolina State University, DORIS (Dynamic Operations and Reusable Information Storage) proposes a new approach to sequencing data-containing DNA, which make up for current impracticalities in the implementation of DNA-based data storage. Their work was published June 2020 in Nature Communications.
“Most of the existing DNA data storage systems rely on polymerase chain reaction (PCR) to access stored data, which is very efficient at copying information but presents some significant challenges,” says Albert Keung, co-corresponding author of the paper. PCR involves drastically increasing and decreasing temperatures of stored genetic material to separate the double stranded DNA. These temperature swings make developing practical technologies for data storage more problematic, and the PCR technique itself gradually uses up the original version of the file being retrieved.

DORIS does things a little differently, by essentially adding a single-strand, tail-like “overhang” to the end of the double-stranded DNA that stores the data. This way, retrieving the data can be achieved at room temperature, without disturbing the double-stranded DNA, making it more feasible in real-world scenarios.
“DORIS allows us to significantly increase the information density of the system, and also makes it easier to scale up to handle really large databases,” says first-author of the work and PhD student Kevin Lin. In short, DORIS doesn’t have to consume the original file in order to read it.
Shannon
Catalog’s device Shannon, named after the “father of information theory” Claude Shannon, managed to store the full English text version of Wikipedia (a total of 16GB) on synthetic DNA molecules in June of 2019. Still at the early prototype stage, this device is a writer, aiming to write data at gigabit per second speeds.
“We perform conventional compression on input data in a standard way, and then we take that compressed representation and further compact it in its DNA encoding scheme by reducing the number of molecules used to represent the previously compressed digital data. In total, [as it stands] we can produce 186 GB of compressed data with Shannon,” says Catalog CTO David Turek.
The team will eventually work on the miniaturization of Shannon, and emphasize that it is still too early to speculate about the form of the device. DNA data storage technology has yet to go commercial, leaving many to wonder: just what are the limitations to its commercial development?
Limitations to the future of data storage
Though DNA data storage has clear advantages over current data storage mediums, it comes with its own set of limitations, the first of which is cost. The cost of synthesizing DNA is still too high at $3500 per 1 megabyte of information to make the technology easily available. And, though efforts are being made to incorporate simpler and faster DNA writing methods with the use of enzymes, time is another limitation as it can take a few hours a day to complete the process of writing and reading data; the key is automation (as Microsoft has achieved), but without an extensive data archive principle, storing data will remain much easier than reading it. Still, we have no doubt that the future of data storage lies in our basic genetic material.
At LeCiiR, our drive for providing our clients with quality, innovative IT solutions matches our excitement for the continued development of DNA-based data storage. We’re keeping an eye on what’s up and coming to keep you up to date in our mission to provide you with security, reliability, and innovation so that you can Live Easy. For questions on our services or any other tech topics, don’t hesitate to contact us and leave your comments.

Recent Comments